工作风格
任务要求:大数据调配及CSV文件导入数据到项目中待使用
现存问题:
01.调配时导致主进程被卡主,其他人登陆网站都成问题
- 超过10万数据量将会把node v8内存(1.4~1.6)挤爆
- csv文件导入和大数据调配的数据无法区分
- 数据导入失败的时候不知道失败原因,导致过多问题移到开发
机遇:
- 调配数据不要求即时返回
- 两种外部数据进入系统殊途同归,可放入同路径,通过同样的方式写入系统,使用不同的字段标识
思路:
- 通过分出进程,将同时间大量数据的写操作分到系统主进程以外的进程
- 通过存储过程将大量数据的mongo搬运剥离node操作,而是用js文件数据库自行运算
- 将两种不同的方式的数据放入同一个工单表,使用定时进程每秒扫描工单表,每秒按要求搬运数据(因为涉及redis key,不能够存储过程的方式纯数据库自行计算搬运),这样可以解决同时间过多数据同时进入node挤爆v8内存,而更多的利用node高并发的优势。
- 每秒搬运1条数据的方式造成的用时过长可以通过将进程集群化的方式,利用服务器多核以及多台的横向展开解决。
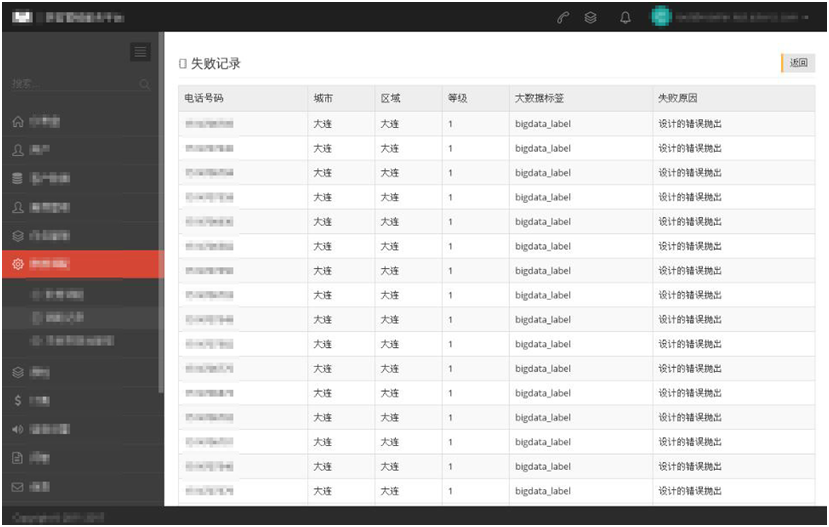
- 每条数据搬运成功后记录进入成功表,失败则记录进入失败表以及失败原因,解决由于数据自身问题导致的导入失败,由业务人员自行处理数据即可,无须由开发检查数据。
设计逻辑:
数据来源分为大数据中间仓和csv文件导入,将2种来源的数据写入工单表,工单表有进程每秒扫描,只要有数据,就执行搬运逻辑,搬运逻辑的数据节点详见上“数据节点”,如果成功,数据则进入工单成功表,如果失败数据进入工单失败表并伴有失败原因。
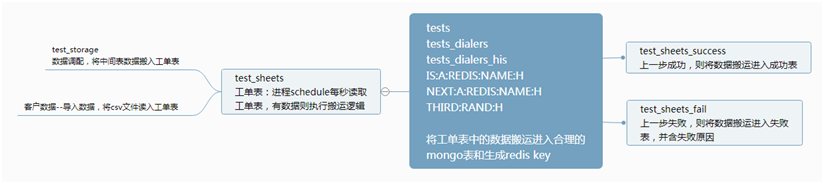
数据节点:
- 增加客户数据主表 test_mongo_name
- 进入拨号盘及其历史表 test_mongo_name_dialers
- 进入redis key PHONEINDEX 和 CUSTOMERINDEX
- 如勾导入选预拨号,应进入预拨号
- 统计指定任务下得客户数量 redis key
页面执行:
- 数据调配:
角色--数据调配--数据调配页面
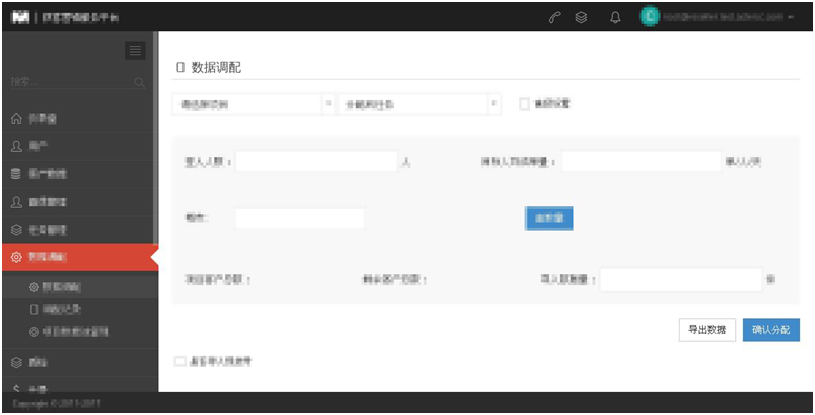
点击确认分配成功后,右上角弹出调配成功的绿条,数据进入搬运状态,可以点击绿条的“调配记录”关键字进入调配记录查看调配进度。
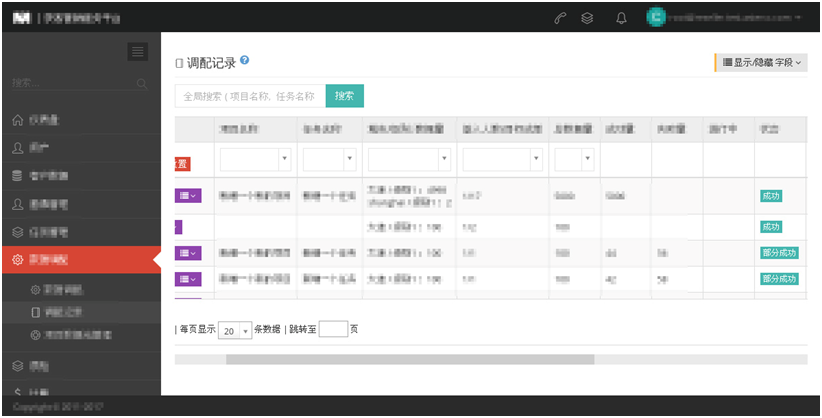
调配记录新增一条记录,并状态在进行中(黄色),进行中显示数量,同时显示成功量及失败量。直至调配结束状态变为成功、失败、部分成功中的一种。
左侧按钮可以查看成功数据及失败数据。
02.csv文件导入数据
角色--客户数据--导入数据功能
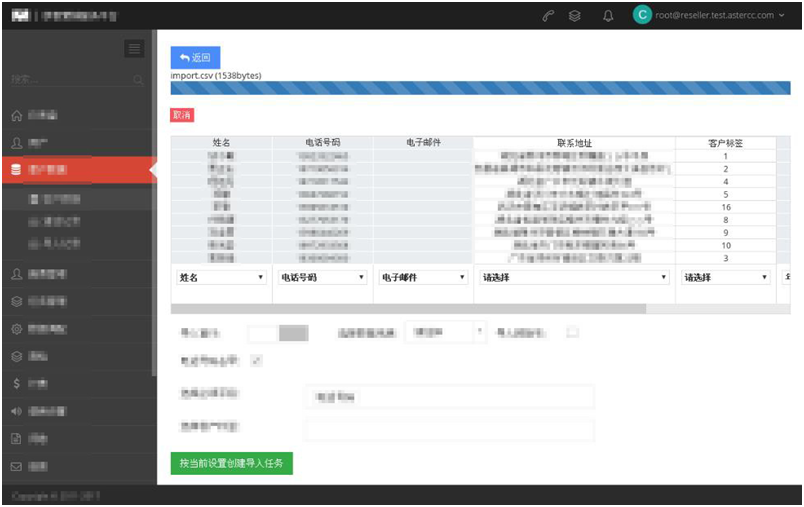
导入后右上角弹出导入成功的绿条,数据进入搬运状态,可以点击绿条的“导入记录”关键字进入导入记录页面查看导入进度。具体情况同调配记录页面。
代码实现:
01. 数据调配,将数据从中间仓搬运进工单表
A 高级调配 server/controllers/test_controller_name.js -> function_name
- 记录表建立任务,任务含搬运相关参数
- 通过js文件的存储过程,将中间表的数据跨库搬运进入工单表,其中将01步骤中的任务id通过参数形式传入存储过程,再在存储过程内获取该任务数据获得多量相关参数,实现搬运过程中数据处理。
- 搬运完成后更新任务为成功
server/controllers/ test_controller_name.js -> function_name
- 通过存储过程,统计中间仓等级城市的分配比例,然后计算参数总数下各城市等级的调配数量。
- 将上一步骤计算结果作为条件传入高级调配函数
02. csv文件导入,将数据从csv文件读取并写入工单表
1)创建后台任务
server/controllers/ test_controller_name.js -> function_name
2)后台任务初始化
server/models/test_model_name.js
3)添加后台任务文件
server/lib/test_lib_name.js
将csv文件的内容读取,组织成合理的数据推入工单表。
tips: 其中导入数据的时候是否应匹配基础字段以外的字段进入 客户资料表(customers),已留出口子编辑相关函数。saveCustomers() {}
03. 工单表进入生产相关mongo表及生成redis key
1)进程schedule每秒执行
server/schedule/main-schedule.js // schedule包,定时执行任务 如果每秒搬运一条数据的话,根据现有业务,如果仅开一个进程,搬运时间可能过长,如: 单次较常用的数据量:5000,耗时:5000/60s = 83分钟 (耗时过长不可接受) 可能存在的单次较大量数据:20000,耗时:20000/60s = 5.5小时(耗时过长不可接受)
于本机进行集群化部署(本机4核)node进程,尝试5000条数数据成功,并且耗时缩短至合理的计算时间(20分钟),并且查询成功都的数据为合理的5000条,没有重复搬运的问题。
故建议该进程集群化部署: 经了解生产服务器一和服务器二压力较大,不适宜部署新的进程,三,四,五较为宽裕,三台机器都是16核的。 5000/60/3/16 = 1.7分钟 20000/60/3/16 = 6.9分钟 请领导评估是否进行集群化部署 </pre> 2)每秒执行扫描工单表 server/schedule/main-schedule.js //引入搬运逻辑程序,扫描工单表,如果有数据,执行搬运程序 3)有数据,执行搬运逻辑 server/schedule/test_schedule_name.js //如果成功,搬入成功表,如果失败,搬入失败表并记录失败原因